Video Face Clustering via Constrained Sparse Representation (ICME2014, Oral)
Abstract
In this paper, we focus on the problem of clustering faces in videos. Different from traditional clustering on a collection of facial images, a video provides some inherent benefits: faces from a face track must belong to the same person and faces from a video frame can not be the same person. These benefits can be used to enhance the clustering performance. More precisely, we convert the above benefits into must-link and cannot-link constraints. These constraints are further effectively incorporated into our novel algorithm, Video Face Clustering via Constrained Sparse Representation (CS-VFC). The CS-VFC utilizes the constraints in two stages, including sparse representation and spectral clustering. Experiments on real-world videos show the improvements of our algorithm over the state-of-the-art methods.

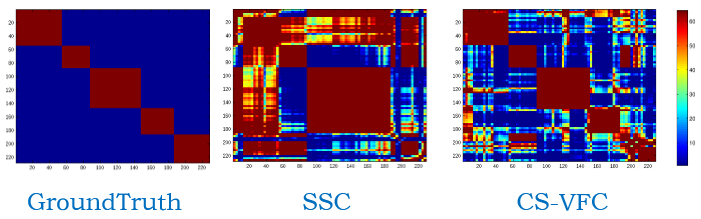
We use the inherent constraints extracting from video in two stages: constrainted sparse representation and constrainted spectral clustering. In conventional sparse representation, a face tends to utilize the faces from the same track as its sparse representation since faces in a same track are more similiar than other tracks. This is redundacy as we know that faces from a track belog to a same person. In the stage of constrainted sparse representation, we focus on exploring the unknown relationship among faces. A comparison of sparse representation of a face on Notting-Hill as follows.

The blue, green and red bars stand for representations from the same track, from the same person and from different persons respectively. Combining with the must-link and cannot-link constraints in spectral clustering, the similarity matrixes on Notting-Hill are illustrated as follows.