Constrained Multi-View Video Face Clustering
Abstract
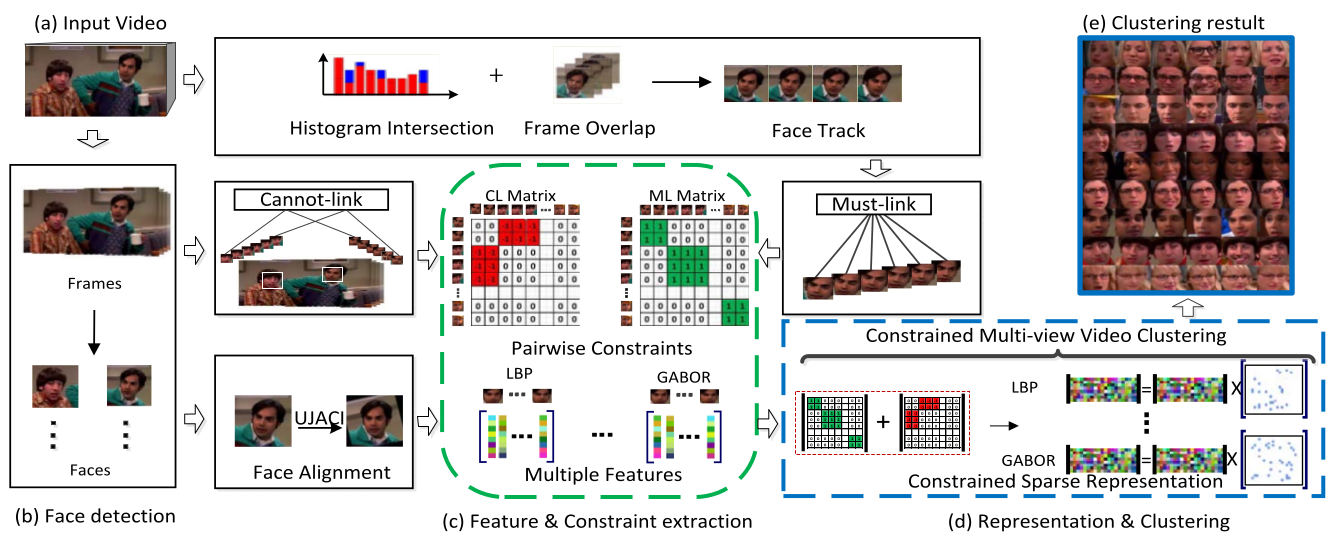
In this paper, we focus on face clustering in videos. To promote the performance of video clustering by multiple intrinsic cues, i.e., pairwise constraints and multiple views, we propose a constrained multi-view video face clustering method under a unified graph-based model. First, unlike most existing video face clustering methods which only employ these constraints in the clustering step, we strengthen the pairwise constraints through the whole video face clustering framework, both in sparse subspace representation and spectral clustering. In the constrained sparse subspace representation, the sparse representation is forced to explore unknown relationships. In the constrained spectral clustering, the constraints are used to guide for learning more reasonable new representations. Second, our method considers both the video face pairwise constraints as well as the multi-view consistence simultaneously. In particular, the graph regularization enforces the pairwise constraints to be respected and the co-regularization penalizes the disagreement among different graphs of multiple views. Experiments on three real-world video benchmark data sets demonstrate the significant improvements of our method over the state-of-the-art methods.